MP3: Difference between revisions
mNo edit summary |
|||
| Line 1: | Line 1: | ||
'''MPEG-1 Audio Layer 3''', more commonly referred to as MP3, is a popular digital audio encoding and lossy compression format, designed to greatly reduce the amount of data required to represent audio, yet still sound like a faithful reproduction of the original uncompressed audio to most listeners. It was invented by a team of European engineers who worked in the framework of the EUREKA 147 DAB digital radio research program, and it became an ISO/IEC standard in 1991. | '''MPEG-1 Audio Layer 3''', more commonly referred to as MP3, is a popular digital audio encoding and lossy compression format, designed to greatly reduce the amount of data required to represent audio, yet still sound like a faithful reproduction of the original uncompressed audio to most listeners. It was invented by a team of European engineers who worked in the framework of the EUREKA 147 DAB digital radio research program, and it became an ISO/IEC standard in 1991. | ||
==History== | == History == | ||
The MP3 algorithm development started in 1987, with a joint cooperation of [http://www.iis.fraunhofer.de/ Fraunhofer IIS-A] and the University of Erlangen. It is standardized as ISO-MPEG Audio Layer-3 (IS 11172-3 and IS 13818-3). | The MP3 algorithm development started in 1987, with a joint cooperation of [http://www.iis.fraunhofer.de/ Fraunhofer IIS-A] and the University of Erlangen. It is standardized as ISO-MPEG Audio Layer-3 (IS 11172-3 and IS 13818-3). | ||
It soon became the de facto standard for lossy audio encoding, due to the high [[compression rates]] (1/11 of the original size, still retaining considerable quality), the high availability of decoders and the low CPU requirements for playback. (486 DX2-100 is enough for real-time decoding) | It soon became the de facto standard for lossy audio encoding, due to the high [[compression rates]] (1/11 of the original size, still retaining considerable quality), the high availability of decoders and the low CPU requirements for playback. (486 DX2-100 is enough for real-time decoding) | ||
It supports [[multichannel]] files (Although there's no implementation yet), [[sampling rate]]s from | It supports [[multichannel]] files (Although there's no implementation yet), [[sampling rate]]s from 16 kHz to 24 kHz (MPEG2 Layer 3) and 32 kHz to 48 kHz (MPEG1 Layer 3) | ||
Formal and informal listening tests have shown that MP3 at the 160-224 kbps range provide encoded results undistinguishable from the original materials in most of the cases. | Formal and informal listening tests have shown that MP3 at the 160-224 kbps range provide encoded results undistinguishable from the original materials in most of the cases. | ||
==Encoding and decoding== | == Encoding and decoding == | ||
===Encoding of MP3 audio=== | === Encoding of MP3 audio === | ||
The MPEG-1 standard does not include a precise specification for an MP3 encoder. The decoding algorithm and file format, as a contrast, are well defined. Implementers of the standard were supposed to devise their own algorithms suitable for removing parts of the information in the raw audio (or rather its MDCT representation in the frequency domain). During encoding 576 time domain samples are taken and are transformed to 576 frequency domain samples. If there is a transient 192 samples are taken instead of 576. This is done to limit the temporal spread of quantization noise accompanying the transient. | The MPEG-1 standard does not include a precise specification for an MP3 encoder. The decoding algorithm and file format, as a contrast, are well defined. Implementers of the standard were supposed to devise their own algorithms suitable for removing parts of the information in the raw audio (or rather its MDCT representation in the frequency domain). During encoding 576 time domain samples are taken and are transformed to 576 frequency domain samples. If there is a transient 192 samples are taken instead of 576. This is done to limit the temporal spread of quantization noise accompanying the transient. | ||
| Line 18: | Line 18: | ||
As a result, there are many different MP3 encoders available, each producing files of differing quality. Comparisons are widely available, so it is easy for a prospective user of an encoder to research the best choice. It must be kept in mind that an encoder that is proficient at encoding at higher bitrates (such as LAME, which is in widespread use for encoding at higher bitrates) is not necessarily as good at other, lower bitrates. | As a result, there are many different MP3 encoders available, each producing files of differing quality. Comparisons are widely available, so it is easy for a prospective user of an encoder to research the best choice. It must be kept in mind that an encoder that is proficient at encoding at higher bitrates (such as LAME, which is in widespread use for encoding at higher bitrates) is not necessarily as good at other, lower bitrates. | ||
===Decoding of MP3 audio=== | === Decoding of MP3 audio === | ||
Decoding, on the other hand, is carefully defined in the standard. Most decoders are "bitstream compliant", meaning that the decompressed output they produce from a given MP3 file will be the same (within a specified degree of rounding tolerance) as the output specified mathematically in the ISO/IEC standard document. The MP3 file has a standard format which is a frame consisting of 384, 576, or 1152 samples (depends on MPEG version and layer) and all the frames have associated header information (32 bits) and side information (9, 17, or 32 bytes, depending on MPEG version and stereo/mono). The header and side information help the decoder to decode the associated Huffman encoded data correctly. | Decoding, on the other hand, is carefully defined in the standard. Most decoders are "bitstream compliant", meaning that the decompressed output they produce from a given MP3 file will be the same (within a specified degree of rounding tolerance) as the output specified mathematically in the ISO/IEC standard document. The MP3 file has a standard format which is a frame consisting of 384, 576, or 1152 samples (depends on MPEG version and layer) and all the frames have associated header information (32 bits) and side information (9, 17, or 32 bytes, depending on MPEG version and stereo/mono). The header and side information help the decoder to decode the associated Huffman encoded data correctly. | ||
Therefore, for the most part, comparison of decoders is almost exclusively based on how computationally efficient they are (i.e., how much memory or CPU time they use in the decoding process). | Therefore, for the most part, comparison of decoders is almost exclusively based on how computationally efficient they are (i.e., how much memory or CPU time they use in the decoding process). | ||
==MP3 file structure== | == MP3 file structure == | ||
[[Image:Mp3filestructure.jpg|thumb|right|500px|Breakdown of an MP3 File's Structure]] | [[Image:Mp3filestructure.jpg|thumb|right|500px|Breakdown of an MP3 File's Structure]] | ||
An MP3 file is made up of multiple MP3 frames which consist of the MP3 header and the MP3 data. This sequence of frames is called an Elementary stream. Frames are independent items: one can cut the frames from a file and an MP3 player would be able to play it. The MP3 data is the actual audio payload. The diagram shows that the MP3 header consists of a sync word which is used to identify the beginning of a valid frame. This is followed by a bit indicating that this is the MPEG standard and two bits that indicate that layer 3 is being used, hence MPEG-1 Audio Layer 3 or MP3. After this, the values will differ depending on the MP3 file. The range of values for each section of the header along with the specification of the header is defined by ISO/IEC 11172-3. Most MP3 files today contain ID3 metadata which precedes or follows the MP3 frames; this is also shown in the diagram. | An MP3 file is made up of multiple MP3 frames which consist of the MP3 header and the MP3 data. This sequence of frames is called an Elementary stream. Frames are independent items: one can cut the frames from a file and an MP3 player would be able to play it. The MP3 data is the actual audio payload. The diagram shows that the MP3 header consists of a sync word which is used to identify the beginning of a valid frame. This is followed by a bit indicating that this is the MPEG standard and two bits that indicate that layer 3 is being used, hence MPEG-1 Audio Layer 3 or MP3. After this, the values will differ depending on the MP3 file. The range of values for each section of the header along with the specification of the header is defined by ISO/IEC 11172-3. Most MP3 files today contain ID3 metadata which precedes or follows the MP3 frames; this is also shown in the diagram. | ||
==Technical information== | == Technical information == | ||
===Codec block diagram=== | === Codec block diagram === | ||
A basic functional block diagram of the MPEG1 layer 3 audio codec is as shown below. | A basic functional block diagram of the MPEG1 layer 3 audio codec is as shown below. | ||
[[Image:Layer3_block.png|frame|center|Block diagram of the MPEG1 layer 3 audio]] | [[Image:Layer3_block.png|frame|center|Block diagram of the MPEG1 layer 3 audio]] | ||
===The hybrid polyphase filterbank=== | === The hybrid polyphase filterbank === | ||
* The polyphase [[filterbank]] is the key component common to all layers of MPEG1 audio compression. The purpose of the polyphase filterbank is to divide the audio signal into 32 equal-width [[frequency]] [[subband]]s, by using a set of [[bandpass filters]] covering the entire audio frequency range (a set of 512 tap FIR Filters). | * The polyphase [[filterbank]] is the key component common to all layers of MPEG1 audio compression. The purpose of the polyphase filterbank is to divide the audio signal into 32 equal-width [[frequency]] [[subband]]s, by using a set of [[bandpass filters]] covering the entire audio frequency range (a set of 512 tap FIR Filters). | ||
[[Image:Poly_samples.png|frame|center|Polyphase filterbank]] | [[Image:Poly_samples.png|frame|center|Polyphase filterbank]] | ||
| Line 62: | Line 62: | ||
* Once the MDCT converts the audio signal into the [[frequency domain]], the [[aliasing]] introduced by the subsampling in the filterbank can be partially cancelled. The decoder has to undo this so that the inverse MDCT can reconstruct the [[subband]] samples in their original aliased form for reconstruction by the synthesis filterbank. | * Once the MDCT converts the audio signal into the [[frequency domain]], the [[aliasing]] introduced by the subsampling in the filterbank can be partially cancelled. The decoder has to undo this so that the inverse MDCT can reconstruct the [[subband]] samples in their original aliased form for reconstruction by the synthesis filterbank. | ||
===The psychoacoustic model:(gathering data, incomplete)=== | === The psychoacoustic model: (gathering data, incomplete) === | ||
* [[Critical band]]s | * [[Critical band]]s | ||
: Much of what is done in Simultaneous [[masking]] is based on the existence of critical bands. The hearing works much like a non-uniform filterbank, and the critical bands can be said to approximate the characteristics of those filters. Critical bands does not really have specific "on" and "off" frequencies, but rather width as a function of [[frequency]] - critical [[bandwidth]]s. | : Much of what is done in Simultaneous [[masking]] is based on the existence of critical bands. The hearing works much like a non-uniform filterbank, and the critical bands can be said to approximate the characteristics of those filters. Critical bands does not really have specific "on" and "off" frequencies, but rather width as a function of [[frequency]] - critical [[bandwidth]]s. | ||
| Line 114: | Line 114: | ||
*** 2.1.1.1 Example for Psychoacoustic Model 2 The processes used by psychoacoustic model 2 are somewhat easier to visualize, so this model will be covered first. Figure 12a shows the result, according to psychoacoustic model 2, of transforming the audio signal to the perceptual domain (63, one-third critical band, partitions) and then applying the spreading function. Note the shift of the sinusoid peak and the expansion of the lowpass noise distribution. The perceptual transformation expands the low frequency region and compresses the higher frequency region. Because the spreading function is applied in a perceptual domain, the shape of the spreading function is relatively uniform as a function of partition. Figure 13 shows a plot of the spreading functions. Figure 12b shows the tonality index for the audio signal as computed by psychoacoustic model 2. Figure 14a shows a plot of the masking threshold as computed by the model based on the spread energy and the tonality index. This figure has plots of the masking threshold both before and after the incorporation of the threshold in quiet to illustrate its impact. Note the threshold in quiet significantly increases the noise masking threshold for the higher frequencies. The human auditory system is much less sensitive in this region. Also note how the sinusoid signal increases the masking threshold for the neighboring frequencies. The masking threshold is computed in the uniform frequency domain instead of the perceptual domain in preparation for the final step of the psychoacoustic model, the calculation of the signal-to-mask ratios (SMR) for each [[subband]]. Figure 14b is a plot of these results and figure 14c is a [[frequency]] plot of a processed audio signal using these SMR’s. In this example the audio compression was severe (768 to 64 kbits/sec) so the coder may not necessarily be able to mask all the [[quantize|quantization]] noise. | *** 2.1.1.1 Example for Psychoacoustic Model 2 The processes used by psychoacoustic model 2 are somewhat easier to visualize, so this model will be covered first. Figure 12a shows the result, according to psychoacoustic model 2, of transforming the audio signal to the perceptual domain (63, one-third critical band, partitions) and then applying the spreading function. Note the shift of the sinusoid peak and the expansion of the lowpass noise distribution. The perceptual transformation expands the low frequency region and compresses the higher frequency region. Because the spreading function is applied in a perceptual domain, the shape of the spreading function is relatively uniform as a function of partition. Figure 13 shows a plot of the spreading functions. Figure 12b shows the tonality index for the audio signal as computed by psychoacoustic model 2. Figure 14a shows a plot of the masking threshold as computed by the model based on the spread energy and the tonality index. This figure has plots of the masking threshold both before and after the incorporation of the threshold in quiet to illustrate its impact. Note the threshold in quiet significantly increases the noise masking threshold for the higher frequencies. The human auditory system is much less sensitive in this region. Also note how the sinusoid signal increases the masking threshold for the neighboring frequencies. The masking threshold is computed in the uniform frequency domain instead of the perceptual domain in preparation for the final step of the psychoacoustic model, the calculation of the signal-to-mask ratios (SMR) for each [[subband]]. Figure 14b is a plot of these results and figure 14c is a [[frequency]] plot of a processed audio signal using these SMR’s. In this example the audio compression was severe (768 to 64 kbits/sec) so the coder may not necessarily be able to mask all the [[quantize|quantization]] noise. | ||
===The psychoacoustic model=== | === The psychoacoustic model === | ||
The psychoacoustic model calculates just-noticeable distortion (JND) profiles for each band in the [[filterbank]]. This noise level is used to determine the actual quantizers and quantizer levels. There are two psychoacoustic models defined by the standard. They can be applied to any layer of the MPEG/Audio algorithm. In practice however, Model 1 has been used for Layers I and II and Model 2 for Layer III. Both models compute a signal-to-mask ratio (SMR) for each band (Layers I and II) or group of bands (Layer III). | The psychoacoustic model calculates just-noticeable distortion (JND) profiles for each band in the [[filterbank]]. This noise level is used to determine the actual quantizers and quantizer levels. There are two psychoacoustic models defined by the standard. They can be applied to any layer of the MPEG/Audio algorithm. In practice however, Model 1 has been used for Layers I and II and Model 2 for Layer III. Both models compute a signal-to-mask ratio (SMR) for each band (Layers I and II) or group of bands (Layer III). | ||
| Line 141: | Line 141: | ||
The masking threshold computed from the spread energy and the tonality index. | The masking threshold computed from the spread energy and the tonality index. | ||
===Processes in the psychoacoustic model=== | === Processes in the psychoacoustic model === | ||
*Performs a 1024-sample [[FFT]]s on each half of a frame (1152 samples) of the input signal, selecting the lower of the two masking thresholds to use for that subband. | * Performs a 1024-sample [[FFT]]s on each half of a frame (1152 samples) of the input signal, selecting the lower of the two masking thresholds to use for that subband. | ||
*Each frequency bin is mapped to its corresponding critical band. | * Each frequency bin is mapped to its corresponding critical band. | ||
*Calculate a tonality index, a measure of whether a signal is more tone-like or noise-like. | * Calculate a tonality index, a measure of whether a signal is more tone-like or noise-like. | ||
*Use a defined spreading function to calculate the masking effect of the signal on neighbouring [[critical band]]s. | * Use a defined spreading function to calculate the masking effect of the signal on neighbouring [[critical band]]s. | ||
*Calculate the final masking threshold for each subband, using the tonality index, the output of the spreading function, and the [[ATH]]. | * Calculate the final masking threshold for each subband, using the tonality index, the output of the spreading function, and the [[ATH]]. | ||
*Calculate the signal-to-mask ratio for each [[subband]], and passes information on to the [[quantize|quantizer]]. | * Calculate the signal-to-mask ratio for each [[subband]], and passes information on to the [[quantize|quantizer]]. | ||
==Pros and cons== | == Pros and cons == | ||
===Pros=== | === Pros === | ||
*Widespread acceptance, support in nearly all hardware audio players and devices | * Widespread acceptance, support in nearly all hardware audio players and devices | ||
*An [[ISO]] standard, part of MPEG specs | * An [[ISO]] standard, part of MPEG specs | ||
*Fast decoding, lower complexity than [[AAC]] or [[ | * Fast decoding, lower complexity than [[Advanced Audio Coding|AAC]] or [[Vorbis]] | ||
*Anyone can create their own implementation (Specs and demo sources available) | * Anyone can create their own implementation (Specs and demo sources available) | ||
*Relaxed licensing schedule | * Relaxed licensing schedule | ||
===Cons=== | === Cons === | ||
*Lower performance/efficiency than modern codecs. | * Lower performance/efficiency than modern codecs. | ||
*Problem cases that trip out all transform codecs. | * Problem cases that trip out all transform codecs. | ||
*Sometimes, maximum bitrate (320kbps) isn't enough. | * Sometimes, maximum bitrate (320kbps) isn't enough. | ||
*No multichannel implementations. | * No multichannel implementations. | ||
*Unusable for high definition audio (sampling rates higher than 48kHz). | * Unusable for high definition audio (sampling rates higher than 48kHz). | ||
==See also== | == See also == | ||
===Techniques used in compression=== | === Techniques used in compression === | ||
*[[Huffman coding]] | * [[Huffman coding]] | ||
*[[Quantization]] | * [[Quantization]] | ||
*[[Joint stereo|M/S matrixing]] | * [[Joint stereo|M/S matrixing]] | ||
*[[Intensity stereo]] | * [[Intensity stereo]] | ||
*[[Channel coupling]] | * [[Channel coupling]] | ||
*Modified discrete cosine transform ([[MDCT]]) | * Modified discrete cosine transform ([[MDCT]]) | ||
*Polyphase filter bank | * Polyphase filter bank | ||
There is a non-standardized form of MP3 called [[MP3Pro]], which takes advantage of [[SBR]] encoding to provide better quality at low bitrates. | There is a non-standardized form of MP3 called [[MP3Pro]], which takes advantage of [[SBR]] encoding to provide better quality at low bitrates. | ||
===Encoders/decoders (supported platforms)=== | === Encoders/decoders (supported platforms) === | ||
*[[LAME]] (Win32/Posix) | * [[LAME]] (Win32/Posix) | ||
*[[Audioactive]] (Win32) | * [[Audioactive]] (Win32) | ||
*[[Blade]] (Win32/Posix) | * [[Blade]] (Win32/Posix) | ||
*[[Xing]] (Win32) | * [[Xing]] (Win32) | ||
*[[Gogo]] (Win32/Posix) | * [[Gogo]] (Win32/Posix) | ||
===Metadata (tags)=== | === Metadata (tags) === | ||
*[[ID3v1]] | * [[ID3v1]] | ||
*[[ID3v1.1]] | * [[ID3v1.1]] | ||
*[[ID3v2]] | * [[ID3v2]] | ||
==Further reading and bibliography== | == Further reading and bibliography == | ||
*[[Best MP3 Decoder]] | * [[Best MP3 Decoder]] | ||
==External links== | == External links == | ||
*[http://www.audiocoding.com/modules/wiki/?page=MP3 MP3 at Audiocoding Wiki] | * [http://www.audiocoding.com/modules/wiki/?page=MP3 MP3 at Audiocoding Wiki] | ||
*[http://www.rjamorim.com/test/mp3-128/results.html Roberto's listening test] featuring MP3 encoders | * [http://www.rjamorim.com/test/mp3-128/results.html Roberto's listening test] featuring MP3 encoders | ||
*[http://uncyclopedia.org/wiki/MP3 MP3 definition at Uncyclopedia] | * [http://uncyclopedia.org/wiki/MP3 MP3 definition at Uncyclopedia] | ||
*[http://en.wikipedia.org/wiki/Mp3 MP3 at Wikipedia] | * [http://en.wikipedia.org/wiki/Mp3 MP3 at Wikipedia] | ||
[[Category: Codecs]] | [[Category: Codecs]] | ||
[[Category: Lossy]] | [[Category: Lossy]] | ||
Revision as of 15:36, 14 June 2007
MPEG-1 Audio Layer 3, more commonly referred to as MP3, is a popular digital audio encoding and lossy compression format, designed to greatly reduce the amount of data required to represent audio, yet still sound like a faithful reproduction of the original uncompressed audio to most listeners. It was invented by a team of European engineers who worked in the framework of the EUREKA 147 DAB digital radio research program, and it became an ISO/IEC standard in 1991.
History
The MP3 algorithm development started in 1987, with a joint cooperation of Fraunhofer IIS-A and the University of Erlangen. It is standardized as ISO-MPEG Audio Layer-3 (IS 11172-3 and IS 13818-3).
It soon became the de facto standard for lossy audio encoding, due to the high compression rates (1/11 of the original size, still retaining considerable quality), the high availability of decoders and the low CPU requirements for playback. (486 DX2-100 is enough for real-time decoding)
It supports multichannel files (Although there's no implementation yet), sampling rates from 16 kHz to 24 kHz (MPEG2 Layer 3) and 32 kHz to 48 kHz (MPEG1 Layer 3)
Formal and informal listening tests have shown that MP3 at the 160-224 kbps range provide encoded results undistinguishable from the original materials in most of the cases.
Encoding and decoding
Encoding of MP3 audio
The MPEG-1 standard does not include a precise specification for an MP3 encoder. The decoding algorithm and file format, as a contrast, are well defined. Implementers of the standard were supposed to devise their own algorithms suitable for removing parts of the information in the raw audio (or rather its MDCT representation in the frequency domain). During encoding 576 time domain samples are taken and are transformed to 576 frequency domain samples. If there is a transient 192 samples are taken instead of 576. This is done to limit the temporal spread of quantization noise accompanying the transient.
This is the domain of psychoacoustics: the study of subjective human perception of sounds.
As a result, there are many different MP3 encoders available, each producing files of differing quality. Comparisons are widely available, so it is easy for a prospective user of an encoder to research the best choice. It must be kept in mind that an encoder that is proficient at encoding at higher bitrates (such as LAME, which is in widespread use for encoding at higher bitrates) is not necessarily as good at other, lower bitrates.
Decoding of MP3 audio
Decoding, on the other hand, is carefully defined in the standard. Most decoders are "bitstream compliant", meaning that the decompressed output they produce from a given MP3 file will be the same (within a specified degree of rounding tolerance) as the output specified mathematically in the ISO/IEC standard document. The MP3 file has a standard format which is a frame consisting of 384, 576, or 1152 samples (depends on MPEG version and layer) and all the frames have associated header information (32 bits) and side information (9, 17, or 32 bytes, depending on MPEG version and stereo/mono). The header and side information help the decoder to decode the associated Huffman encoded data correctly.
Therefore, for the most part, comparison of decoders is almost exclusively based on how computationally efficient they are (i.e., how much memory or CPU time they use in the decoding process).
MP3 file structure

An MP3 file is made up of multiple MP3 frames which consist of the MP3 header and the MP3 data. This sequence of frames is called an Elementary stream. Frames are independent items: one can cut the frames from a file and an MP3 player would be able to play it. The MP3 data is the actual audio payload. The diagram shows that the MP3 header consists of a sync word which is used to identify the beginning of a valid frame. This is followed by a bit indicating that this is the MPEG standard and two bits that indicate that layer 3 is being used, hence MPEG-1 Audio Layer 3 or MP3. After this, the values will differ depending on the MP3 file. The range of values for each section of the header along with the specification of the header is defined by ISO/IEC 11172-3. Most MP3 files today contain ID3 metadata which precedes or follows the MP3 frames; this is also shown in the diagram.
Technical information
Codec block diagram
A basic functional block diagram of the MPEG1 layer 3 audio codec is as shown below.

The hybrid polyphase filterbank
- The polyphase filterbank is the key component common to all layers of MPEG1 audio compression. The purpose of the polyphase filterbank is to divide the audio signal into 32 equal-width frequency subbands, by using a set of bandpass filters covering the entire audio frequency range (a set of 512 tap FIR Filters).

- PolyphaseFilterbankFormula
- Audio is processsed by frames of 1152 samples per audio channel. The polyphase filter groups 3 groups of 12 samples (3x12=36) samples per subband as seen from the picture above (3x12x32 subbands=1152 samples).
- The polyphase filter bank and its inverse are not lossless transformations. Even without quantization, the inverse transformation cannot perfectly recover the original signal. However by design the error introduced by the filter bank is small and inaudible.
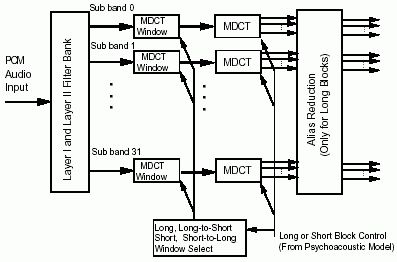
MDCT
MDCT formula:

![{\displaystyle X(m)=\sum _{k=0}^{n-1}f(k)x(k)\cos[{{\pi \over {2n}}({2k+1+{n \over 2}})({2m+1})}],~m=0...{n \over 2}-1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fc8ec640a4445be8ce9eeda421451cde25a09249)
- Layer 3 compensates for some of the filter bank deficiencies by processing the filter bank output with a Modified Discrete Cosine Transform (MDCT). The polyphase filterbank and the MDCT are together called as the Hybrid filterbank. The Hybrid FilterBank adapts to the signal characteristics (block switching depending on the signal etc.).
- The 32 subband signals are subdivided further in frequency content by applying a 18-spectral point or 6-spectral point MDCT. Layer 3 specifies two different MDCT block lenghts: a long block (18 spectral points) or a short block (6 spectral points).
- Long Blocks: Long blocks have a higher frequency resolution. Each subband is transformed into 18 spectral coefficients by MDCT, yielding a maximum of 576 spectral coefficients (32x18=576 spectral lines) each representing a bandwidth of 41.67Hz at 48kHz sampling rate. At 48kHz sampling rate a long block has a time resolution of about x ms. There is a 50% overlap between successive transform windows, so the window size is 36 for long blocks.
- Short Blocks: Short blocks have a higher time resolution. Short block length is one third of a long block and used for transients to provide better time (temporal) resolution. Each subband is transformed into 6 spectral coefficients by MDCT, yielding a maximum of 192 spectral coefficients (32x6=192 spectral lines) each representing a bandwidth of 125Hz at 48kHz sampling rate. At 48kHz sampling rate a short block has impulse response of 18.6ms. There is a 50% overlap between successive transform windows, so the window size is 12 for short blocks.
- Time resolutions of long blocks and time resolution of short blocks are not constants, but jitter depending on the position of the sample in the transformed block. See here for diagrams showing the average time resolutions of different codecs.

- Block switching (MDCT window switching) is triggered by psycho acoustics.
- For a given frame of 1152 samples, the MDCT's can all have the same block length (long or short) or have a mixed-block mode (mixed-block mode for Lame is in development).
- Unlike only the polyphase filterbank, without quantization the MDCT transformation is lossless.
- Once the MDCT converts the audio signal into the frequency domain, the aliasing introduced by the subsampling in the filterbank can be partially cancelled. The decoder has to undo this so that the inverse MDCT can reconstruct the subband samples in their original aliased form for reconstruction by the synthesis filterbank.
The psychoacoustic model: (gathering data, incomplete)
- Much of what is done in Simultaneous masking is based on the existence of critical bands. The hearing works much like a non-uniform filterbank, and the critical bands can be said to approximate the characteristics of those filters. Critical bands does not really have specific "on" and "off" frequencies, but rather width as a function of frequency - critical bandwidths.
- Tonality estimation
- Spreading function
- Masking does not only occur within the critical band, but also spreads to neighboring bands. A spreading function SF(z,a) can be defined, where z is the frequency and a the amplitude of a masker. This function would give a masking threshold produced by a single masker for neighboring frequencies. The simplest function would be a triangular function with slopes of +25 and -10 dB / Bark, but a more sophisticated one is highly nonlinear and depends on both frequency and amplitude of masker.
- Simultaneous masking
- Simultaneous masking is a frequency domain phenomenon where a low level signal, e.g, a smallband noise (the maskee) can be made inaudible by simultaneously occuring stronger signal (the masker), e.g, a pure tone,if masker and maskee are close enough to each other in frequency. A masking threshold can be measured below which any signal will not be audible. The masking threshold depends on the sound pressure level (SPL) and the frequency of the masker, and on the characteristics of the masker and maskee. The slope of the masking threshold is steeper towards lower frequencies,i.e., higher frequencies are more easily masked.
- Without a masker, a signal is inaudible if its SPL is below the threshold of quiet, which depends on frequency and covers a dynamic range of more than 60 dB. We have just described masking by only one masker. If the source signal consists of many simultaneous maskers, a global masking threshold can be computed that describes the threshold of just noticeable distortions as a function of frequency. The calculation of the global masking threshold is based on the high resolution short term amplitude spectrum of the audio or speech signal, sufficient for critical band based analysis, and is determined in audio coding via 512 or 1024 point FFT. In a first step all individual masking thresholds are calculated, depending on signal level, type of masker(noise or tone), and frequency range. Next the global masking threshold is determined by adding all individual thresholds and the threshold in quiet (adding this later threshold ensures that the computed global masking threshold is not below the threshold in quiet). The effects of masking reaching over critical band bounds must be included in the calculation. Finally the global signal-to-mask ratio (SMR) is determined as the ratio of the maximum of signal power and global masking threshold.
- Temporal
- In addition to simultaneous masking two time domain phenomena also play an important role in human auditory perception, pre-masking and post-masking. The temporal masking effects occur before and after a masking signal has been switched on and off, respectively. The duration when pre-masking applies is less than -or as newer results indicate, significantly less than-one tenth that of the post-masking, which is in the order of 50 to 200 msec. Both pre and post-masking are being exploited in the ISO/MPEG audio coding algorithm.
- It uses either a separate filterbank or combines the calculation of energy values (for the masking calculations) and the main filter bank. The output of the perceptual model consists of values for the masking threshold or the allowed noise for each coder partition. If the quantization noise can be kept below the masking threshold, then the compression results should be indistinguishable from the original signal.
- Masking threshold
- Masking raises the threshold of hearing, and compressors take advantage of this effect by raising the noise floor, which allows the audio waveform to be expressed with fewer bits. The noise floor can only be raised at frequencies at which there is effective masking.
- The equal widths of the subbands do not accurately reflect the human auditory system's frequency dependent behavior. The width of a "critical band" as a function of frequency is a good indicator of this behavior. Many psychoacoustic effects are consistent with a critical band frequency scaling. For example, both the perceived loudness of a signal and its audibility in the presence of a masking signal is different for signals within one critical band than for signals that extend over more than one critical band. Figure 2 compares the polyphase filter bandwidths with the width of these critical bands. At lower frequencies a single subband covers several critical bands.
- The MPEG/audio algorithm compresses the audio data in large part by removing the acoustically irrelevant parts of the audio signal. That is, it takes advantage of the human auditory system's inability to hear quantization noise under conditions of auditory masking. This masking is a perceptual property of the human auditory system that occurs whenever the presence of a strong audio signal makes a temporal or spectral neighborhood of weaker audio signals imperceptible. A variety of psychoacoustic experiments corroborate this masking phenomenon[13].
- Empirical results also show that the human auditory system has a limited, frequency dependent, resolution. This frequency dependency can be expressed in terms of critical band widths which are less than 100Hz for the lowest audible frequencies and more than 4kHz at the highest. The human auditory system blurs the various signal components within a critical band although this system's frequency selectivity is much finer than a critical band.
- The psychoacoustic model analyzes the audio signal and computes the amount of noise masking available as a function of frequency ,14,15,16,17. The masking ability of a given signal component depends on its frequency position and its loudness. The encoder uses this information to decide how best to represent the input audio signal with its limited number of code bits. The MPEG/audio standard provides two example implementations of the psychoacoustic model.
- Below is a general outline of the basic steps involved in the psychoacoustic calculations for either model. Differences between the two models will be highlighted.
- Time align audio data. There is one psychoacoustic evaluation per frame. The audio data sent to the psychoacoustic model must be concurrent with the audio data to be coded. The psychoacoustic model must account for both the delay of the audio data through the filterbank and a data offset so that the relevant data is centered within the psychoacoustic analysis window.
- Convert audio to a frequency domain representation. The psychoacoustic model should use a separate, independent, timeto- frequency mapping instead of the polyphase filter bank because it needs finer frequency resolution for an accurate calculation of the masking thresholds.
- Layer II and III use a 1,152 sample frame size so the 1,024 sample window does not provide complete coverage. While ideally the analysis window should completely cover the samples to be coded, a 1,024 sample window is a reasonable compromise. Samples falling outside the analysis window generally will not have a major impact on the psychoacoustic evaluation.
- For Layers II and III, the model computes two 1,024 point psychoacoustic calculations for each frame. The first calculation centers the first half of the 1,152 samples in the analysis window and the second calculation centers the second half. The model combines the results of the two calculations by using the higher of the two signal-to-mask ratios for each subband. This in effect selects the lower of the two noise masking thresholds for each subband.
- Process spectral values in groupings related to critical band widths. To simplify the psychoacoustic calculations, both models process the frequency values in perceptual quanta.
- Psychoacoustic model 2 never actually separates tonal and non-tonal components. Instead, it computes a tonality index as a function of frequency. This index gives a measure of whether the component is more tone-like or noise-like. Model 2 uses this index to interpolate between pure tone-masking-noise and noise-masking-tone values. The tonality index is based on a measure of predictability. Model 2 uses data from the previous two analysis windows to predict, via linear extrapolation, the component values for the current window. Tonal components are more predictable and thus will have higher tonality indices. Because this process relies on more data, it is more likely to better discriminate between tonal and non-tonal components than the model 1 method.
- Apply a spreading function. The masking ability of a given signal spreads across its surrounding critical band. The model determines the noise masking thresholds by first applying an empirically determined masking (model 1) or spreading function (model 2) to the signal components.
- Set a lower bound for the threshold values. Both models include an empirically determined absolute masking threshold, the threshold in quiet. This threshold is the lower bound on the audibility of sound.
- Find the masking threshold for each subband. Model 2 selects the minimum of the masking thresholds covered by the subband only where the band is wide relative to the critical band in that frequency region. It uses the average of the masking thresholds covered by the subband where the band is narrow relative to the critical band. Model 2 is not less accurate for the higher frequency subbands because it does not concentrate the non-tonal components.
- Calculate the signal-to-mask ratio. The psychoacoustic model computes the signal-to-mask ratio as the ratio of the signal energy within the subband (or, for Layer III , a group of bands) to the minimum masking threshold for that subband. The model passes this value to the bit (or noise) allocation section of the encoder.
- 2.1.1.1 Example for Psychoacoustic Model 2 The processes used by psychoacoustic model 2 are somewhat easier to visualize, so this model will be covered first. Figure 12a shows the result, according to psychoacoustic model 2, of transforming the audio signal to the perceptual domain (63, one-third critical band, partitions) and then applying the spreading function. Note the shift of the sinusoid peak and the expansion of the lowpass noise distribution. The perceptual transformation expands the low frequency region and compresses the higher frequency region. Because the spreading function is applied in a perceptual domain, the shape of the spreading function is relatively uniform as a function of partition. Figure 13 shows a plot of the spreading functions. Figure 12b shows the tonality index for the audio signal as computed by psychoacoustic model 2. Figure 14a shows a plot of the masking threshold as computed by the model based on the spread energy and the tonality index. This figure has plots of the masking threshold both before and after the incorporation of the threshold in quiet to illustrate its impact. Note the threshold in quiet significantly increases the noise masking threshold for the higher frequencies. The human auditory system is much less sensitive in this region. Also note how the sinusoid signal increases the masking threshold for the neighboring frequencies. The masking threshold is computed in the uniform frequency domain instead of the perceptual domain in preparation for the final step of the psychoacoustic model, the calculation of the signal-to-mask ratios (SMR) for each subband. Figure 14b is a plot of these results and figure 14c is a frequency plot of a processed audio signal using these SMR’s. In this example the audio compression was severe (768 to 64 kbits/sec) so the coder may not necessarily be able to mask all the quantization noise.
The psychoacoustic model
The psychoacoustic model calculates just-noticeable distortion (JND) profiles for each band in the filterbank. This noise level is used to determine the actual quantizers and quantizer levels. There are two psychoacoustic models defined by the standard. They can be applied to any layer of the MPEG/Audio algorithm. In practice however, Model 1 has been used for Layers I and II and Model 2 for Layer III. Both models compute a signal-to-mask ratio (SMR) for each band (Layers I and II) or group of bands (Layer III).
The more sophisticated of the two, Model 2, will be discussed. The steps leading to the computation of the JND profiles is outlined below. 1. Time-align audio data
The psychoacoustic model must estimate the masking thresholds for the audio data that are to be quantized. So, it must account for both the delay through the filterbank and a data offset so that the relevant data is centered within the psychoacoustic analysis window. For the Layer III algorithm, time-aligning the psychoacoustic model with the filterbank demands that the data fed to the model be delayed by 768 samples. 2. Spectral analysis and normalization.
A high-resolution spectral estimate of the time-aligned data is essential for an accurate estimation of the masking thresholds in the critical bands. The low frequency resolution of the filterbank leaves no option but to compute an independent time-to-frequency mapping via a fast Fourier Transform (FFT). A Hanning window is applied to the data to reduce the edge effects of the transform window.
Layer III operates on 1152-sample data frames. Model 2 uses a 1024- point window for spectral estimation. Ideally, the analysis window should completely cover the samples to be coded. The model computes two 1024-point psychoacoustic calculations. On the first pass, the first 576 samples are centered in the analysis window. The second pass centers the remaining samples. The model combines the results of the two calculations by using the more stringent of the two JND estimates for bit or noise allocation in each subband.
Since playback levels are unknown3, the sound-pressure level (SPL) needs to be normalized. This implies clamping the lowest point in the absolute threshold of hearing curves to +/- 1-bit amplitude. 3. Grouping of spectral values into threshold calculation partitions.
The uniform frequency decomposition and poor selectivity of the filterbank do not reflect the response of the BM. To accurately model the masking phenomenon characteristic of the BM, the spectral values are grouped into a large number of partitions. The exact number of threshold partitions depends on the choice of sampling rate. This transformation provides a resolution of approximately either 1 FFT line or 1/3 critical band, whichever is smaller. At low frequencies, a single line of the FFT will constitute a partition, while at high frequency|frequencies many lines are grouped into one. 4. Estimation of tonality indices.
It is necessary to identify tonal and non-tonal (noise-like) components because the masking abilities of the two types of signals differ. Model 2 does not explicitly separate tonal and non-tonal components[16]. Instead, it computes a tonality index as a function of frequency. This is an indicator of the tone-like or noise-like nature of the spectral component. The tonality index is based on a measure of predictability. Linear extrapolation is used to predict the component values of the current window from the previous two analysis windows. Model 2 uses this index to interpolate between pure tone-masking-noise and noise-masking-tone values. Tonal components are more predictable and thus have a higher tonality index. As this process has memory, it is more likely to discriminate better between tonal and non-tonal components, unlike psychoacoustic Model 116. 5. Simulation of the spread of masking on the BM.
A strong signal component affects the audibility of weaker components in the same critical band and the adjacent bands. Model 2 simulates this phenomenon by applying a Spreading function to spread the energy of any critical band into its surrounding bands. On the Bark scale, the spreading function has a constant shape as a function of partition number, with slopes of +25 and –10 dB per Bark. 6. Set a lower bound for the threshold values.
An empirically determined absolute masking threshold, the threshold in quiet, is used as a lower bound on the audibility of sound. 7. Determination of masking threshold per subband.
At low frequencies, the minimum of the masking thresholds within a subband is chosen as the threshold value. At higher frequencies, the average of the thresholds within the subband is selected as the masking threshold. Model 2 has the same accuracy for the higher subbands as for low frequency ones because it does not concentrate non-tonal components16. 8. Pre echo detection and window switching decision[17]?. 9. Calculation of the signal-to-mask ratio (SMR).
SMR is calculated as a ratio of signal energy within the subband (for Layers I and II) or a group of subbands (Layer III) to the minimum threshold for that subband. This is the final output of the psychoacoustic model.
The masking threshold computed from the spread energy and the tonality index.
Processes in the psychoacoustic model
- Performs a 1024-sample FFTs on each half of a frame (1152 samples) of the input signal, selecting the lower of the two masking thresholds to use for that subband.
- Each frequency bin is mapped to its corresponding critical band.
- Calculate a tonality index, a measure of whether a signal is more tone-like or noise-like.
- Use a defined spreading function to calculate the masking effect of the signal on neighbouring critical bands.
- Calculate the final masking threshold for each subband, using the tonality index, the output of the spreading function, and the ATH.
- Calculate the signal-to-mask ratio for each subband, and passes information on to the quantizer.
Pros and cons
Pros
- Widespread acceptance, support in nearly all hardware audio players and devices
- An ISO standard, part of MPEG specs
- Fast decoding, lower complexity than AAC or Vorbis
- Anyone can create their own implementation (Specs and demo sources available)
- Relaxed licensing schedule
Cons
- Lower performance/efficiency than modern codecs.
- Problem cases that trip out all transform codecs.
- Sometimes, maximum bitrate (320kbps) isn't enough.
- No multichannel implementations.
- Unusable for high definition audio (sampling rates higher than 48kHz).
See also
Techniques used in compression
- Huffman coding
- Quantization
- M/S matrixing
- Intensity stereo
- Channel coupling
- Modified discrete cosine transform (MDCT)
- Polyphase filter bank
There is a non-standardized form of MP3 called MP3Pro, which takes advantage of SBR encoding to provide better quality at low bitrates.
Encoders/decoders (supported platforms)
- LAME (Win32/Posix)
- Audioactive (Win32)
- Blade (Win32/Posix)
- Xing (Win32)
- Gogo (Win32/Posix)
Metadata (tags)
Further reading and bibliography
External links
- MP3 at Audiocoding Wiki
- Roberto's listening test featuring MP3 encoders
- MP3 definition at Uncyclopedia
- MP3 at Wikipedia